Andrej Karpathy — co-founder of OpenAI, former AI lead at Tesla, and the person who coined "vibe coding" — has shared a significant shift in how he uses LLMs. He is now spending more of his token budget building structured, persistent knowledge bases than generating code. The workflow is simple in architecture but profound in implication.
Source: Andrej Karpathy (@karpathy) on X — x.com/karpathy/status/2039805659525644595
What was shared
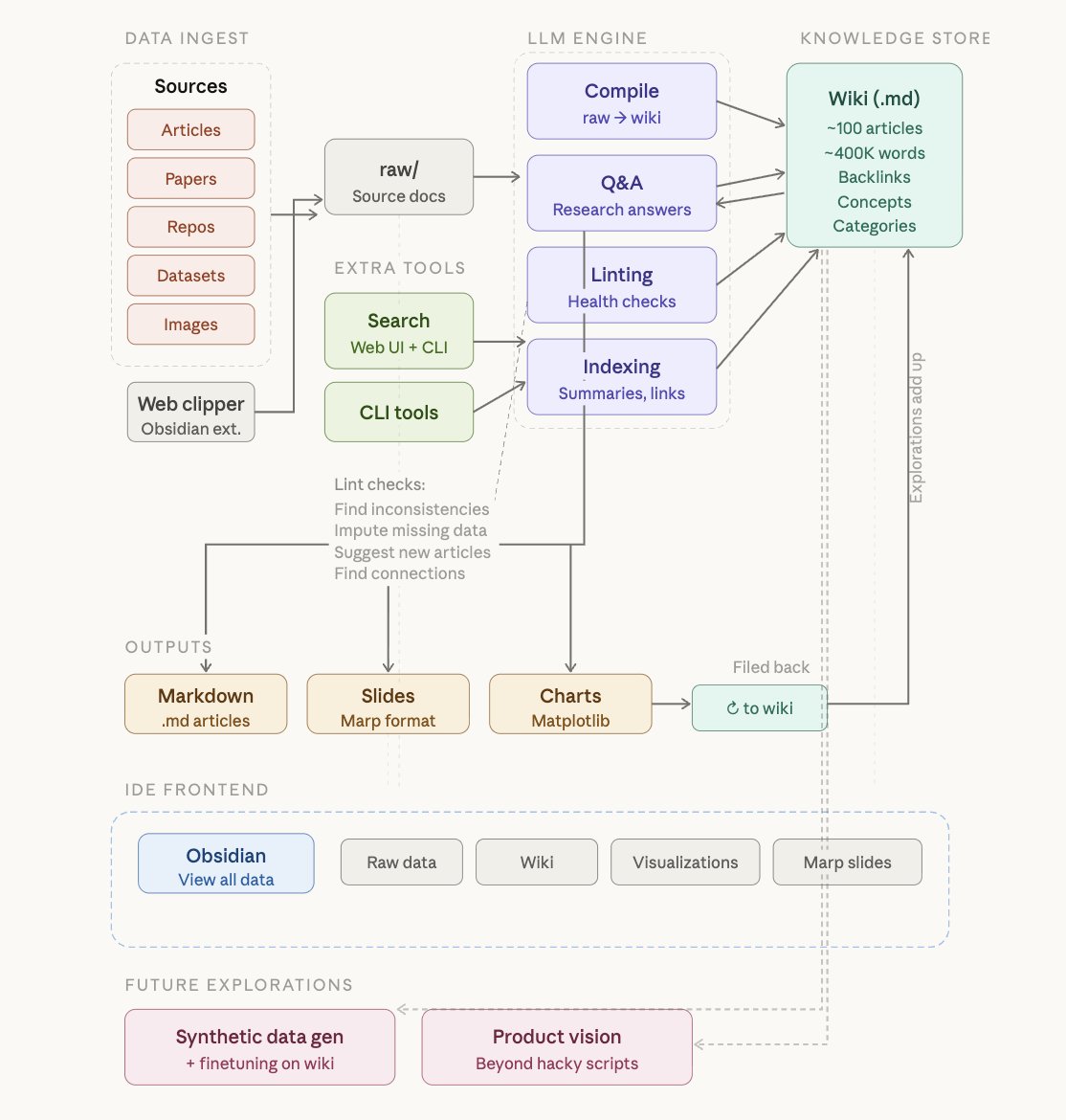
Karpathy describes a system where raw source material — articles, papers, GitHub repositories, datasets, images — is dropped into a raw/ directory. An LLM then incrementally "compiles" all of it into a structured wiki: a collection of .md (Markdown) files organised into a directory structure. The wiki includes summaries, concept articles, backlinks, and cross-references between ideas.
The key principle: the LLM writes and maintains all the data in the wiki. Karpathy says he rarely touches it directly.
"A large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge." — Andrej Karpathy
The four-stage workflow
Data ingest — Raw source documents (articles, papers, repos, datasets, images) go into a raw/ directory. Karpathy uses the Obsidian Web Clipper browser extension to convert web articles into Markdown files and downloads related images locally so the LLM can reference them directly via vision.
Compilation — An LLM incrementally reads the raw directory and writes a structured wiki. It generates summaries, categorises content into concepts, authors encyclopedia-style articles, and creates backlinks between related ideas. No embeddings or vector databases are involved.
Q&A — Once the wiki reaches critical mass (Karpathy's example: approximately 100 articles and 400,000 words on a single research topic), the LLM can answer complex, multi-step research questions against it. He notes the LLM auto-maintains index files and brief document summaries, making retrieval surprisingly efficient at this scale without RAG pipelines.
Linting — Periodic "health checks" where the LLM scans the wiki for inconsistencies, imputes missing data, surfaces new connections, and proposes new article candidates. The community described this as a knowledge base that heals itself.
Key numbers
Tools used
Why this is different from RAG
Traditional knowledge management for AI relies on vector databases and retrieval-augmented generation (RAG) — embedding documents, computing similarity scores, fetching chunks. Karpathy's approach replaces this with a human-readable, file-based wiki that the LLM compiles and maintains as a living document. At the scale of a personal knowledge base, a large context window combined with auto-maintained indexes is sufficient. The community debate it sparked: the AI industry may have over-indexed on vector databases for problems that are fundamentally about structure, not similarity.
Why this matters for AI-Ready Schools?
This is one of the most important workflow signals for education in recent months. Here is why.
The shift from code to knowledge is the shift from doing to thinking. Karpathy's observation that he is now spending more tokens on knowledge than code maps directly onto what we want children to do — use AI not just to produce outputs, but to build and refine understanding over time.
ZION's Research Hub — Research Buddy, Chat with PDFs, Text Playground — is already pointing in this direction. The Karpathy workflow shows what a mature version of that looks like: a living knowledge system that grows with the learner, not a one-shot query tool.
The concept of a student wiki maintained by AI is a natural next evolution of the Cypher 360° student view. Instead of just tracking knowledge state, imagine a personal knowledge base per student — built collaboratively with their AI companion — that becomes richer with every project, paper, and concept they explore.
The "LLM as compiler, human as director" model is exactly what the Agentic Thinking framework describes as Workflow Orchestration. Children who learn to set up, curate, and query a personal knowledge base are practising a form of thinking that will matter for decades.
The linting concept has a direct classroom parallel. Running health checks on a knowledge base — finding gaps, inconsistencies, and new connections — is the same cognitive process as revision, peer review, and metacognition. AI makes it continuous rather than periodic.
Karpathy closes with a line worth noting: "I think there is room here for an incredible new product instead of a hacky collection of scripts." For AIRS, that product could be built for K-12 — a student knowledge base that grows from Grade 1 to Grade 12, maintained by their AI companion, and owned entirely by the child.
Tags: Andrej Karpathy · LLM Knowledge Bases · Knowledge Management · Obsidian · Markdown · AI Workflows · No-RAG · Agentic AI · Ed-tech implications · Personal AI















